3. Compiler-Aided Design of Embedded Computers
3.1 Introduction
Embedded systems are computing platforms that are used inside a product whose main function is different than general-purpose computing. Cell phones and multipoint fuel injection systems in cars are examples of embedded systems. Embedded systems are characterized by application-specific and multidimensional design constraints. While decreasing time to market and the need for frequent upgrades are pushing embedded system designs toward programmable implementations, these stringent requirements demand that designs be highly customized. To customize embedded systems, standard design features of general-purpose processors are often omitted, and several new features are introduced in embedded systems to meet all the design constraints simultaneously.
Consequently, software development for embedded systems has become a very challenging task. Traditionally humans used to code for embedded systems directly in assembly language, but now with the software content reaching multimillion lines of code and increasing at the rate of 100 times every decade, compilers have the onus of generating code for embedded systems. With embedded system designs still being manually customized, compilers have a dual responsibility: first to exploit the novel architectural features in the embedded systems, and second to avoid the loss due to missing standard architectural features. Existing compiler technology falls tragically short of these goals.
While the task of the compiler is challenging in embedded systems, it has been shown time and again that whenever possible, a compiler can have a very significant impact on the power, performance, and so on of the embedded system. Given that the compiler can have a very significant impact on the design constraints of embedded systems. Consequently, it is only logical to include the compiler during the design of the embedded system. Existing embedded system design techniques do not include the compiler during the design space exploration. While it is possible to use ad hoc methods to include the compiler's effects during the design of a processor, a systematic methodology to perform compiler-aware embedded systems design is needed. Such design techniques are called compiler-aided design techniques.
This chapter introduces our compiler-in-the-loop (CIL) design methodology, which systematically includes compiler effects to design embedded processors. The core capability in this methodology is a design space exploration (DSE) compiler. A DSE compiler is different from a normal compiler in that a DSE compiler has heuristics that are parameterized on the architectural parameters of the processor architecture. While typical compilers are built for one microarchitecture, a DSE compiler can generate good-quality code for a range of architectures. A DSE compiler takes the architecture description of the processor as an input, along with the application source code, and generates an optimized executable of the application for the architecture described.
The rest of the chapter is organized as follows. In Section 3.2, we describe our whole approach of using a compiler for processor design. In particular, we attempt to design the popular architectural feature, in embedded processors, called horizontally partitioned cache (HPC), using our CIL design methodology. Processors with HPC have two caches at the same level of memory hierarchy, and wisely partitioning the data between the two caches can achieve significant energy savings. Since there is no existing effective compiler technique to achieve energy reduction using HPCs, in Section 3.4, we first develop a compiler technique to partition data for HPC architectures to achieve energy reduction. The compilation technique is generic, in the sense that it is not for specific HPC parameters but works well across HPC parameters. Being armed with a parametric compilation technique for HPCs, Section 3.5 embarks upon the quest designs an embedded processor by choosing the HPC parameters using inputs from the compiler.
Finally, Section 3.6 summarizes this chapter.
3.2 Compiler-Aided Design of Embedded Systems
The fundamental difference between an embedded system and a general-purpose computer system is in the usage of the system. An embedded system is very application specific. Typically a set of applications are installed on an embedded system, and the embedded system continues to execute those applications throughout its lifetime, while general-purpose computing systems are designed to be much more flexible to allow and enable rapid evolution in the application set. For example, the multipoint fuel injection systems in automobiles are controlled by embedded systems, which are manufactured and installed when the car is made. Throughout the life of the car, the embedded system performs no other task than controlling the multipoint fuel injection into the engine. In contrast, a general-purpose computer performs a variety of tasks that change very frequently. We continuously install new games, word processing software, text editing software, movie players, simulation tools, and so on, on our desktop PCs. With the popularity of automatic updating features in PCs, upgrading has become more frequent than ever before. It is the application-specific nature of embedded systems that allows us to perform more aggressive optimizations through customization.
3.2.1 Design Constraints on Embedded Systems
Most design constraints on the embedded systems come from the environment in which the embedded system will operate. Embedded systems are characterized by application-specific, stringent, and multidimensional design constraints:
Application-specific design constraints:: The design constraints on embedded systems differ widely; they are very application specific. For instance, the embedded system used in interplanetary surveillance apparatus needs to be very robust and should be able to operate in a much wider range of temperatures than the embedded system used to control an mp3 player. Multidimensional design constraints:: Unlike general-purpose computer systems, embedded systems have constraints in multiple design dimensions: power, performance, cost, weight, and even form. A new constraint for handheld devices is the thickness of handheld electronic devices. Vendors only want to develop ske designs in mp3 players and cell phones. Stringent design constraints:: The constraints on embedded systems are much more stringent than on general-purpose computers. For instance, a handheld has much tighter constraint on weight of the system than a desktop system. This comes from the portability requirements of handhelds such as mp3 players. While people want to carry their mp3 players everywhere with them, desktops are not supposed to be moved very often. Thus, even if a desktop weighs a bound more, it does not matter much, while in an mp3 player every once matters.
3.2.2 Highly Customized Designs of Embedded Systems
Owing to the increasing market pressures of short time to market and frequent upgrading, embedded system designers want to implement their embedded systems using programmable components, which provide faster and easier development and upgrades through software. The stringent, multidimensional, and application-specific constraints on embedded systems force the embedded systems to be highly customized to be able to meet all the design constraints simultaneously. The programmable component in the embedded system (or the embedded processor) is designed very much like general-purpose processors but is more specialized and customized to the application domain. For example, even though register renaming increases performance in processors by avoiding false data dependencies, embedded processors may not be able to employ it because of the high power consumption and the complexity of the logic. Therefore, embedded processors might deploy a "trimmed-down" or "light-weight" version of register renaming, which provides the best compromise on the important design parameters.
In addition, designers often implement irregular design features, which are not common in general-purpose processors but may lead to significant improvements in some design parameters for the relevant set of applications. For example, several cryptography application processors come with hardware accelerators that implement the complex cryptography algorithm in the hardware. By doing so, the cryptography applications can be made faster and consume less power but may not have any noticeable impact on normal applications. Embedded processor architectures often have such application-specific "idiosyncratic" architectural features.
Last, some design features that are present in general-purpose processors may be entirely missing in embedded processors. For example, support for prefetching is now a standard feature in general-purpose processors, but it may consume too much energy and require too much extra hardware to be appropriate in an embedded processor.
To summarize, embedded systems are characterized by application-specific, multidimensional, and stringent constraints, which result in the embedded system designs being highly customized to meet all the design constraints simultaneously.
3.2.3 Compilers for Embedded Systems
High levels of customization and the presence of idiosyncratic design features in embedded processors create unique challenges for their compilers. This leaves the compiler for the embedded processor in a very tough spot. Compilation techniques for general-purpose processors may not be suitable for embedded processors for several reasons, some of which are listed below:
Different ISA:: Typically, embedded processors have different instruction set architectures (ISAs) than general-purpose processors. While IA32 and PowerPC are the most popular ISAs in the general-purpose processors, ARM and MIPS are the most popular instruction sets in embedded processors.
The primary reason for the difference in ISAs is that embedded processors are often built from the ground up to optimize for their design constraints. For instance, the ARM instruction set has been designed to reduce the code size. The code footprint of an application compiled in ARM instructions is very small. Differentoptimization goals:: Even if compilers can be modified to compile for a different instruction set, the optimization goals of the compilers for general-purpose processors and embedded processors are different. Most general-purpose compiler technology aims toward high performance and less compile time. However, for many embedded systems, energy consumption and code size may very important goals. For battery-operated handheld devices energy consumption is very important and, due to the limited amount of RAM size in the embedded system, the code size may be very important. In addition, for most embedded systems compile time may not be an issue, since the applications are compiled on a server--somewhere other than the embedded system--and only the binaries are loaded on the embedded system to execute as efficiently as possible. Limited compiler technology:: Even though techniques may be present to exploit the regular design features in general-purpose processors, compiler technology to exploit the "customized" version of the architectural technique may be absent. For example, predication is a standard architectural feature employed in most high-end processors. In predication, the execution of each instruction is conditional on the value of a bit in the processor state register, called the condition bit. The condition bit can be set by some instructions. Predication allows a dynamic decision about whether to execute an instruction. However, because of the architectural overhead of implementing predication, sometimes very limited support for predication is deployed in embedded processors. For example, in the Starcore architecture [36], there is no condition bit, there is just a special conditional move instruction (e.g., cond_move R1 R2, R3 R4), whose semantics are: if (R1 > 0) move R1 R3, else move R1 R4. To achieve the same effect as predication, the computations should be performed locally, and then the conditional instruction can be used to dynamically decide to commit the result or not. In such cases, the existing techniques and heuristics developed for predication do not work. New techniques have to be developed to exploit this "flavor" of predication in the architecture. The first challenge in developing compilers for embedded processors is therefore to enhance the compiler technology to exploit novel and idiosyncratic architectural features present in embedded processors. Avoid penalty due to missing design features:: Several embedded systems simply omit some architectural features that are common in general-purpose processors. For example, the support for prefetching may be absent in an embedded processor. In such cases, the challenge is to minimize the power and performance loss resulting from the missing architectural feature.
To summarize, code generation for embedded processors is extremely challenging because of their nonregular architectures and their stringent multidimensional constraints.
3.2.4 Compiler-Assisted Embedded System Design
While code generation for embedded systems is extremely challenging, a good compiler for an embedded system can significantly improve the power, performance, etc. of the embedded system. For example, a compiler technique to support partial predication can achieve almost the same performance as complete predication [13]. Compiler-aided prefetching in embedded systems with minimal support for prefetching can be almost as effective as a complete hardware solution [37].
3.2.4.1 Compiler as a CAD Tool
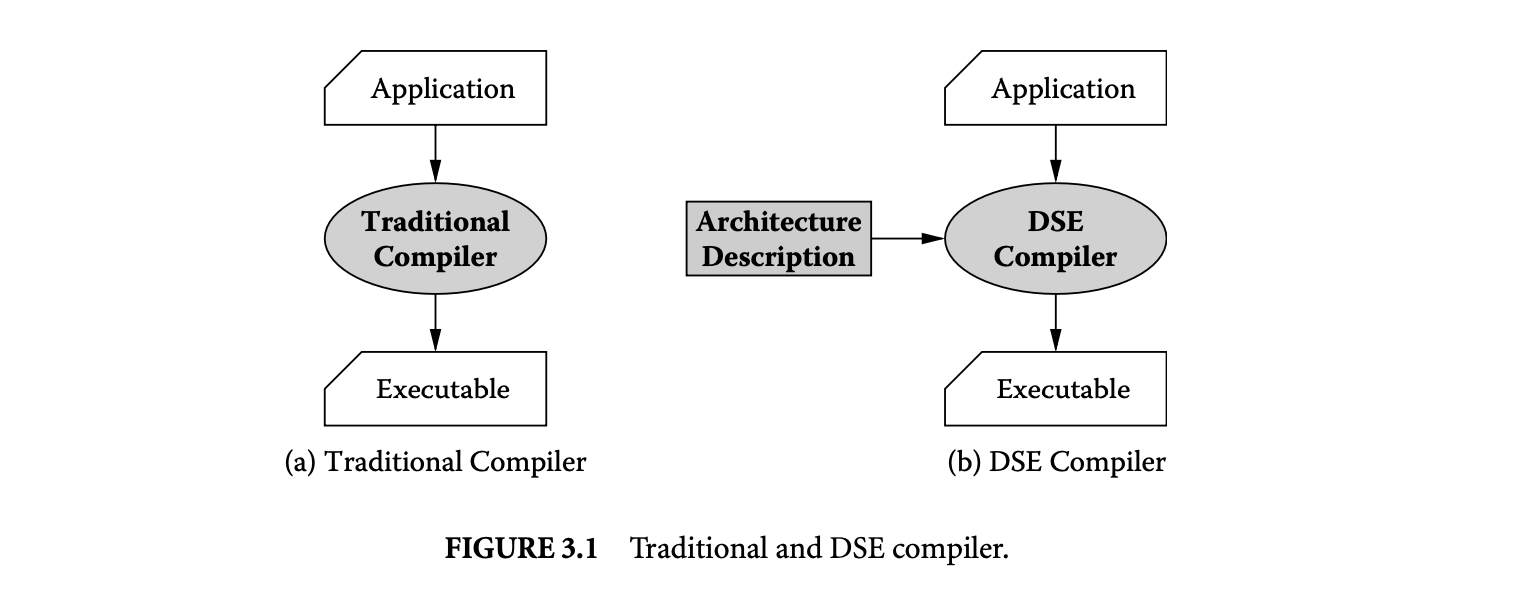
Given the significance of the compiler on processor power and performance, it is only logical that the compiler must play an important role in embedded processor design. To be able to use compilers to design processors, the key capability required is an architecture-sensitive compiler, or what we call a DSE compiler. It should be noted here that the DSE compiler we use and need here is conceptually different than a normal compiler. As depicted in Figure 3.1, a normal compiler is for a specific processor; it takes the source code of the application and generates code that is as fast as possible, as low-power consuming as possible, and so on for that specific processor. A DSE compiler is more generic; it is for a range of architectures. A DSE compiler takes the source code of the application, and the processor architecture description as input, and generates code for the processor described. The main difference between a normal compiler and a DSE compiler is in the heuristics used. The heuristics deployed in a traditional compiler may not have a large degree of parameterization. For example, the register allocator in the compiler for a machine that has 32 registers needs to be efficient in allocating just 32 registers, while a DSE compiler should be able to efficiently register allocate using any number of registers. One example is that the instruction scheduling heuristic of a DSE compiler will be parameterized on the processor pipeline description, while in a normal compiler, it can be fixed. Another example is the register allocation heuristic in the compiler. The register allocation algorithm in a compiler for a machine that has 32 registers needs to be efficient in allocating just 32 registers, while a DSE compiler should be able to efficiently register allocate using any number of registers. No doubt, all compilers have some degree of parameterizations that allow some degree of compiler code reuse when developing a compiler for a different architecture. DSE compilers have an extremely high degree of parametrization and allow large-scale compiler code reuse.
Additionally, while a normal compiler can have ad hoc heuristics to generate code, a DSE compiler needs to truthfully and accurately model the architecture and have compilation heuristics that are parameterized on the architecture model. For example, simple scheduling rules are often used to generate code for a particular bypass configuration. The scheduling rules, for example, a dependent load instruction should always be separated by two or more cycles after the add instruction, work for the specific bypass configuration. A DSE compiler will have to model the processor pipeline and bypasses as a graph or a grammar and generate code that selects instructions that form a path in the pipeline or a legitimate word in the grammar.
The DSE compiler gets the processor description in Architecture Description Language (ADL). While there is a significant body of research in developing ADLs[1, 4, 5, 8, 9, 20, 21, 38] to serve as golden specification for simulation, verification, synthesis, and so on, here we need an ADL that can describe the processor at an abstraction that the compiler needs. We use the EXPRESSION ADL [10, 25] to parameterize our DSE compiler that we call EXPRESS [13].
3.2.4.2 Traditional Design Space Exploration
Figure 3.2 models the traditional design methodology for exploring processor architectures. In the traditional approach, the application is compiled once to generate an executable. The executable is then
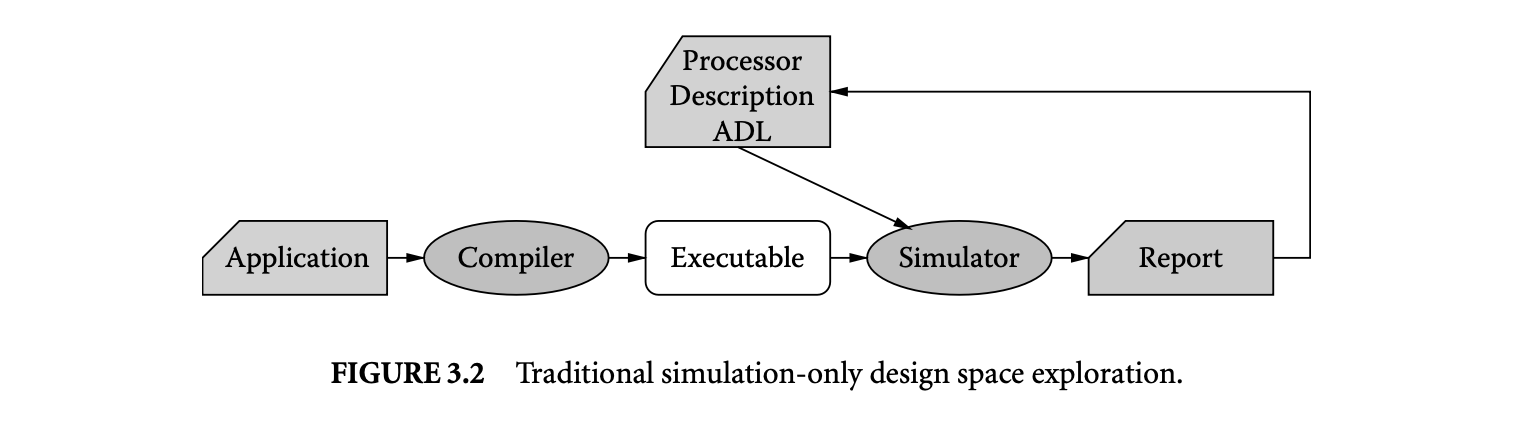
simulated over various architectures to choose the best architecture. We call such traditional design methodology simulation-only (SO) DSE. The SO DSE of embedded systems does not incorporate compiler effects in the embedded processor design. However, the compiler effects on the eventual power and performance characteristics can be incorporated in embedded processor design in an ad hoc manner in the existing methodology. For example, the hand-generated code can be used to reflect the code the actual compiler will eventually generate. This hand-generated code can be used to evaluate the architecture. However, such a scheme may be erroneous and result in suboptimal design decisions. A systematic way to incorporate compiler hints while designing the embedded processor is needed.
3.2.4.3 Compiler-in-the-Loop Exploration
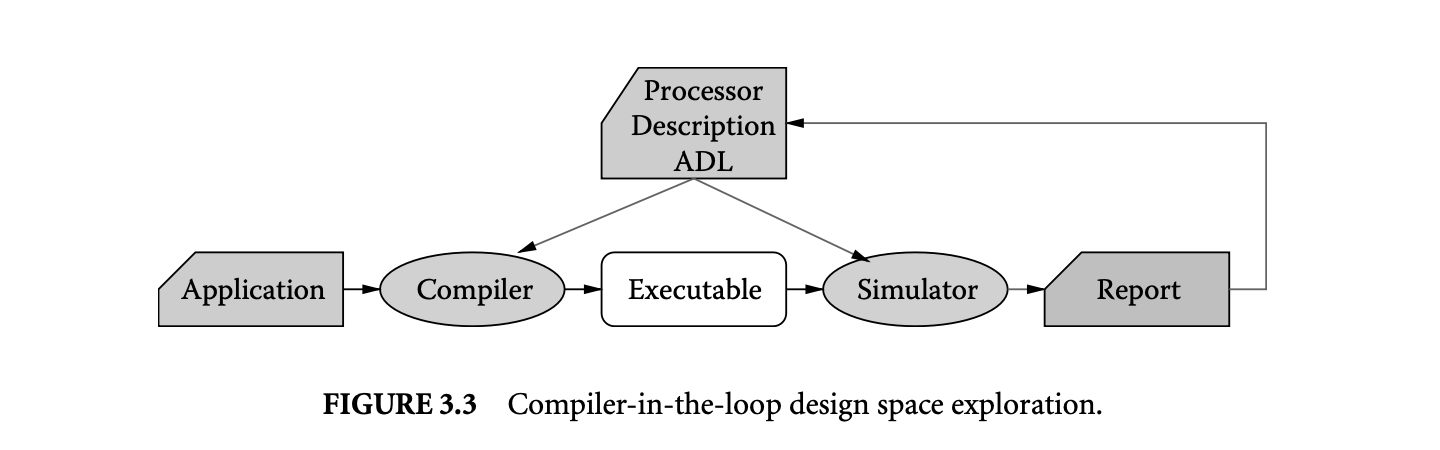
Figure 3.3 describes our proposed CIL schema for DSE. In this scheme, for each architectural variation, the application is compiled (using the DSE compiler), and the executable is simulated on a simulator of the architectural variation. Thus, the evaluation of the architecture incorporates the compiler effects in a systematic manner. The overhead CIL DSE is the extra compilation time during each exploration step, but that is insignificant relative to the simulation time.
We have developed various novel compilation techniques to exploit architectural features present in embedded processors and demonstrate the need and usefulness of CIL DSE at several abstractions of processor design, as shown in Figure 3.4: at the processor instruction set design abstraction, at the processor pipeline design abstraction, at the memory design abstraction, and at the processor memory interaction abstraction.
At the processor pipeline design abstraction, we developed a novel compilation technique for generating code for processors with partial bypassing. Partial bypassing is a popular microarchitectural feature present in embedded systems because although full bypassing is the best for performance, it may have significant area, power, and wiring complexity overheads. However, partial bypassing in processors poses a challenge for compilers, as no techniques accurately detect pipeline hazards in partially bypassed processors. Our operation-table-based modeling of the processor allows us to accurately detect all kinds of pipeline hazards and generates up to 20% better performing code than a bypass-insensitive compiler [23, 32, 34].

During processor design, the decision to add or remove a bypass is typically made by designer's intuition or SO DSE. However, since the compiler has significant impact on the code generated for a bypass configuration, the SO DSE may be significantly inaccurate. The comparison of our CIL with SO DSE demonstrates that not only do these two explorations result in significantly different evaluations of each bypass configuration, but they also exhibit different trends for the goodness of bypass configurations. Consequently, the traditional SO DSE can result in suboptimal design decisions, justifying the need and usefulness of our CIL DSE of bypasses in embedded systems [26, 31].
At the instruction set design abstraction, we first develop a novel compilation technique to generate code to exploit reduced bit-width instruction set architectures (rISAs). rISA is a popular architectural feature in which the processor supports two instruction sets. The first instruction set is composed of instructions that are 32 bits wide, and the second is a narrow instruction set composed of 16-bit-wide instructions. rISAs were originally conceived to reduce the code size of the application. If the application can be expressed in the narrow instructions only, then up to 50% code compression can be achieved. However, since the narrow instructions are only 16 bits wide, they implement limited functionality and can access only a small subset of the architectural registers. Our register pressure heuristic consistently achieves 35% code compression as compared to 14% achieved by existing techniques [12, 30].
In addition, we find out that the code compression achieved is very sensitive on the narrow instruction set chosen and the compiler. Therefore, during processor design, the narrow instruction set should be designed very carefully. We employ our CIL DSE technique to design the narrow instruction set. We find that correctly designing the narrow instruction set can double the achievable code compression [9, 29].
At the processor pipeline-memory interface design abstraction, we first develop a compilation technique to aggregate the processor activity and therefore reduce the power consumption when the processor is stalled. Fast and high-bandwidth memory buses, although best for performance, can have very high costs, energy consumption, and design complexity. As a result, embedded processors often employ slow buses. Reducing the speed of the memory bus increases the time a processor is stalled. Since the energy consumption of the processor is lower in the stalled state, the power consumption of the processor decreases. However, there is further scope for power reduction of the processor by switching the processor to IDLE state while it is stalled. However, switching the state of the processor takes 180 processor cycles in the Intel XScale, while the largest stall duration observed in the qsort benchmark of the MiBench suite is less than 100 processor cycles. Therefore, it is not possible to switch the processor to a low-power IDLE state during naturally occurring stalls during the application execution. Our technique aggregates the memory stalls of a processor into a large enough stall so that the processor can be switched to the low-power IDLE state. Our technique is able to aggregate up to 50,000 stall cycles, and by switching the processor to the low-power IDLE state, the power consumption of the processor can be reduced by up to 18% [33].
There is a significant difference in the processor power consumption between the SO DSE and CIL DSE. SO DSE can significantly overestimate the processor power consumption for a given memory bus configuration. This bolsters the need and usefulness of including compiler effects during the exploration and therefore highlights the need for CIL DSE.
This chapter uses a very simple architectural feature called horizontally partitioned caches (HPCs) to demonstrate the need and usefulness of CIL exploration design methodology. HPC is a popular memory architectural feature present in embedded systems in which the processors have multiple (typically two) caches at the same level of memory hierarchy. Wisely partitioning data between the caches can result in performance and energy improvements. However, existing techniques target performance improvements and achieve energy reduction only as a by-product. First we will develop energy-oriented data partitioning techniques to achieve high degrees of energy reduction, with a minimal hit on performance [35], and then we show that compared to SO DSE of HPC configurations, CIL DSE results in discovering HPC configurations that result in significantly less energy consumption.
3.3 Horizontally Partitioned Cache
Caches are one of the major contributors of not only system power and performance, but also of the embedded processor area and cost. In the Intel XScale [17], caches comprise approximately 90% of the transistor count and 60% of the area and consume approximately 15% of the processor power [3]. As a result, several hardware, software, and cooperative techniques have been proposed to improve the effectiveness of caches.
Horizontally partitioned caches are one such feature. HPCs were originally proposed in 1995 by Gonzalez et al. [6] for performance improvement. HPCs are a popular microarchitectural feature and have been deployed in several current processors such as the popular Intel StrongArm [16] and the Intel XScale [17]. However, compiler techniques to exploit them are still in their nascent stages.
A horizontally partitioned cache architecture maintains multiple caches at the same level of hierarchy, but each memory address is mapped to exactly one cache. For example, the Intel XScale contains two data caches, a 32KB main cache and a 2KB mini-cache. Each virtual page can be mapped to either of the data caches, depending on the attributes in the page table entry in the data memory management unit. Henceforth in this paper we will call the additional cache the mini-cache and the original cache the main cache.
The original idea behind such cache organization is the observation that array accesses in loops often have low temporal locality. Each value of an array is used for a while and then not used for a long time. Such array accesses sweep the cache and evict the existing data (like frequently accessed stack data) out of the cache. The problem is worse for high-associativity caches that typically employ first-in-first-out page replacement policy. Mapping such array accesses to the small mini-cache reduces the pollution in the main cache and prevents thrashing, leading to performance improvements. Thus, a horizontally partitioned cache is a simple, yet powerful, architectural feature to improve performance. Consequently, most existing approaches for partitioning data between the horizontally partitioned caches aim at improving performance.
In addition to performance improvement, horizontally partitioned caches also result in a reduction in the energy consumption due to two effects. First, reduction in the total number of misses results in reduced energy consumption. Second, since the size of the mini-cache is typically small, the energy consumed per access in the mini-cache is less than that in the large main cache. Therefore, diverting some memory accesses to the mini-cache leads to a decrease in the total energy consumption. Note that the first effect is in line with the performance goal and was therefore targeted by traditional performance improvement optimizations. However, the second effect is orthogonal to performance improvement. Therefore, energy reduction by the second effect was not considered by traditional performance-oriented techniques. As we show in this paper, the second effect (of a smaller mini-cache) can lead to energy improvements even in the presence of slight performance degradation. Note that this is where the goals of performance improvement and energy improvement diverge.
3.4 Compiler for Horizontally Partitioned Cache
3.4.1 HPC Compiler Framework
The problem of energy optimization for HPCs can be translated into a data partitioning problem. The data memory that the program accesses is divided into pages, and each page can be independently and exclusively mapped to exactly one of the caches. The compiler's job is then to find the mapping of the data memory pages to the caches that leads to minimum energy consumption.
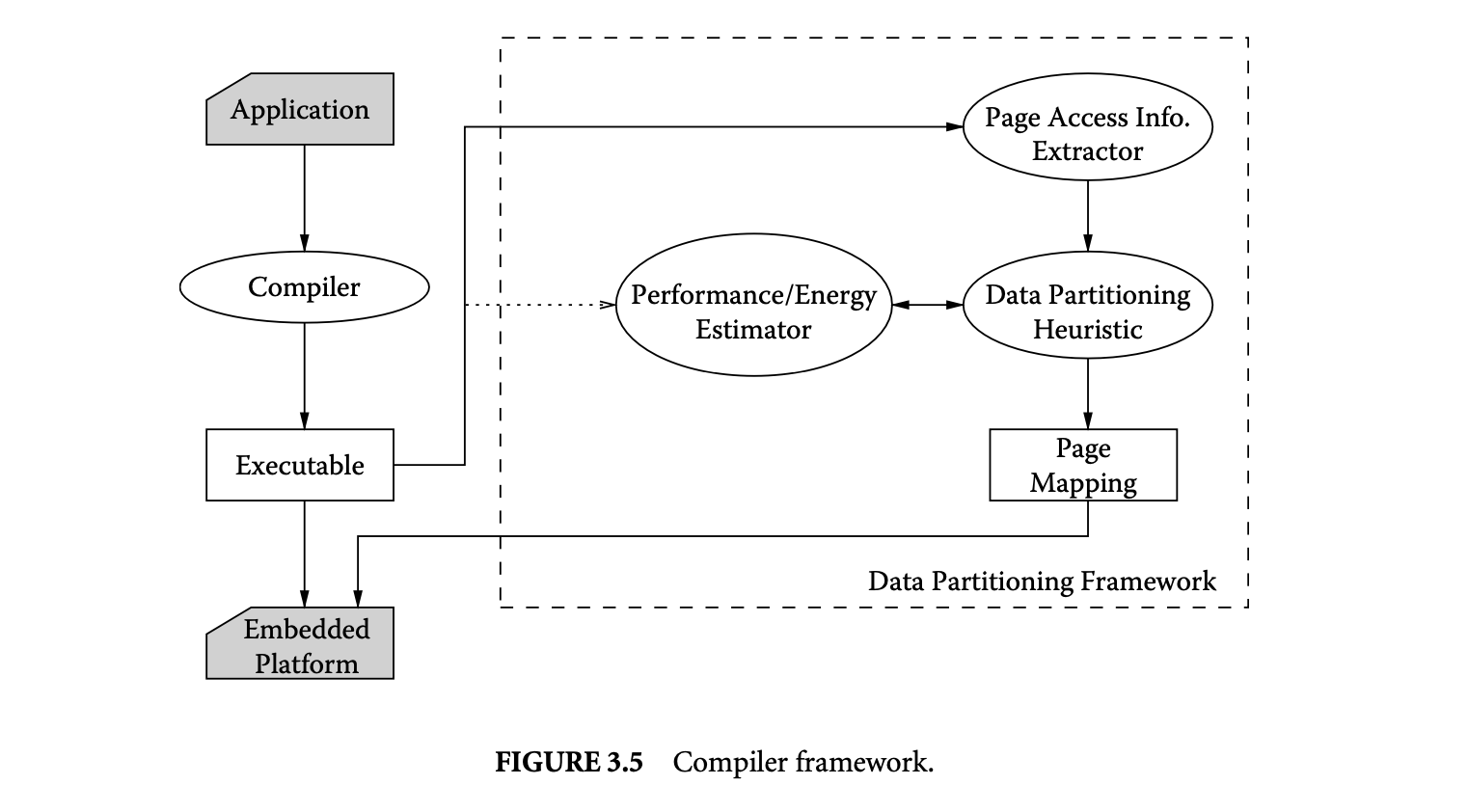
As shown in Figure 3.5, we first compile the application and generate the executable. The page access information extractor calculates the number of times each page is accessed during the execution of the program. Then it sorts the pages in decreasing order of accesses to the pages. The complexity of simulation used to compute the number of accesses to each page and sorting the pages is , where is the number of data memory accesses, and is the number of pages accessed by the application.
The data partitioning heuristic finds the best mapping of pages to the caches that minimizes the energy consumption of the target embedded platform. The data partitioning heuristic can be tuned to obtain the best-performing, or minimal energy, data partition by changing the cost function performance/energy estimator.
The executable together with the page mapping are then loaded by the operating system of the target platform for optimized execution of the application.
3.4.2 Experimental Framework
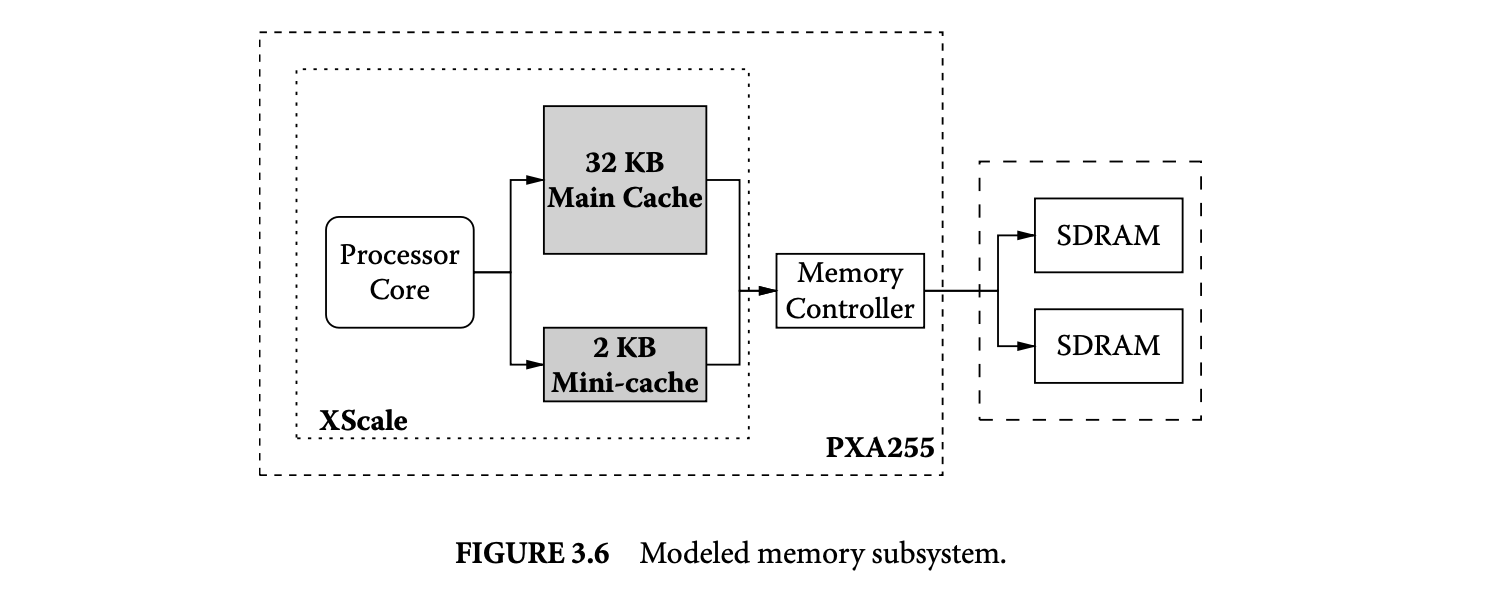
We have developed a framework to evaluate data partitioning algorithms to optimize the memory latency or the memory subsystem energy consumption of applications. We have modified sim-safe simulator from the SimpleScalar toolset [2] to obtain the number of accesses to each data memory page. This implements our page access information extractor in Figure 3.5. To estimate the performance/energy of an application for a given mapping of data memory pages to the main cache and the mini-cache, we have developed performance and energy models of the memory subsystem of a popular PDA, the HP iPAQ h4300 [14].
Figure 3.6 shows the memory subsystem of the iPAQ that we have modeled. The iPAQ uses the Intel PXA255 processor [15] with the XScale core [17], which has a 32KB main cache and 2KB mini-cache. PXA255 also has an on-chip memory controller that communicates with via an off-chip bus. We have modeled the low-power 32MB Micron MT48V8M32LF [24] SDRAM as the off-chip memory. Since the iPAQ has 64MB of memory, we have modeled two SDRAMs.
We use the memory latency as the performance metric. We estimate the memory latency as , where and are the number of accesses, and and are the number of misses in the mini-cache and the main cache, respectively. We obtain these numbers using the sim-cache simulator [2], modified to model HPCs. The miss penalty was estimated as 25 processor cycles, taking into account the processor frequency (400 MHz), the memory bus frequency (100 MHz), the SDRAM access latency in power-down mode (6 memory cycles), and the memory controller delay (1 processor cycle).
We use the memory subsystem energy consumption as the energy metric. Our estimate of memory energy consumption has three components: energy consumed by the caches, energy consumed by off-chip busses, and energy consumed by the main memory (SDRAMs). We compute the energy consumed in the caches using the access and miss statistics from the modified sim-cache results. The energy consumed per access for each of the caches is computed using eCACTI [23]. Compared to CACTI [28], eCACTI provides better energy estimates for high-associativity caches, since it models sense-amps more accurately and scales device widths according to the capacitive loads. We have used linear extrapolation on cache size to estimate energy consumption of the mini-cache, since neither CACTI nor eCACTI model caches with less than eight sets.
We use the Printed Circuit Board (PCB) and layout recommendations of the PXA255 and Intel 440MX chipset [18, 16] and the relation between , and [19] to compute the the energy consumed by the external memory bus in a read/write burst as shown in Table 3.1.
We used the parameters shown in Table 3.2 from the MICRON MT48V8M32LF SDRAM to compute the energy consumed by the SDRAM per read/write burst operation (cache line read/write), shown in Table 3.2.
We perform our experiments on applications from the MiBench suite [7] and an implementation of the H.263 encoder [22]. To compile our benchmarks we used GCC with all optimizations turned on.


3.4.3 Simple Greedy Heuristics Work Well for Energy Optimization
In this section, we develop and explore several data partitioning heuristics with the aim of reducing the memory subsystem energy consumption.
3.4.3.1 Scope of Energy Reduction
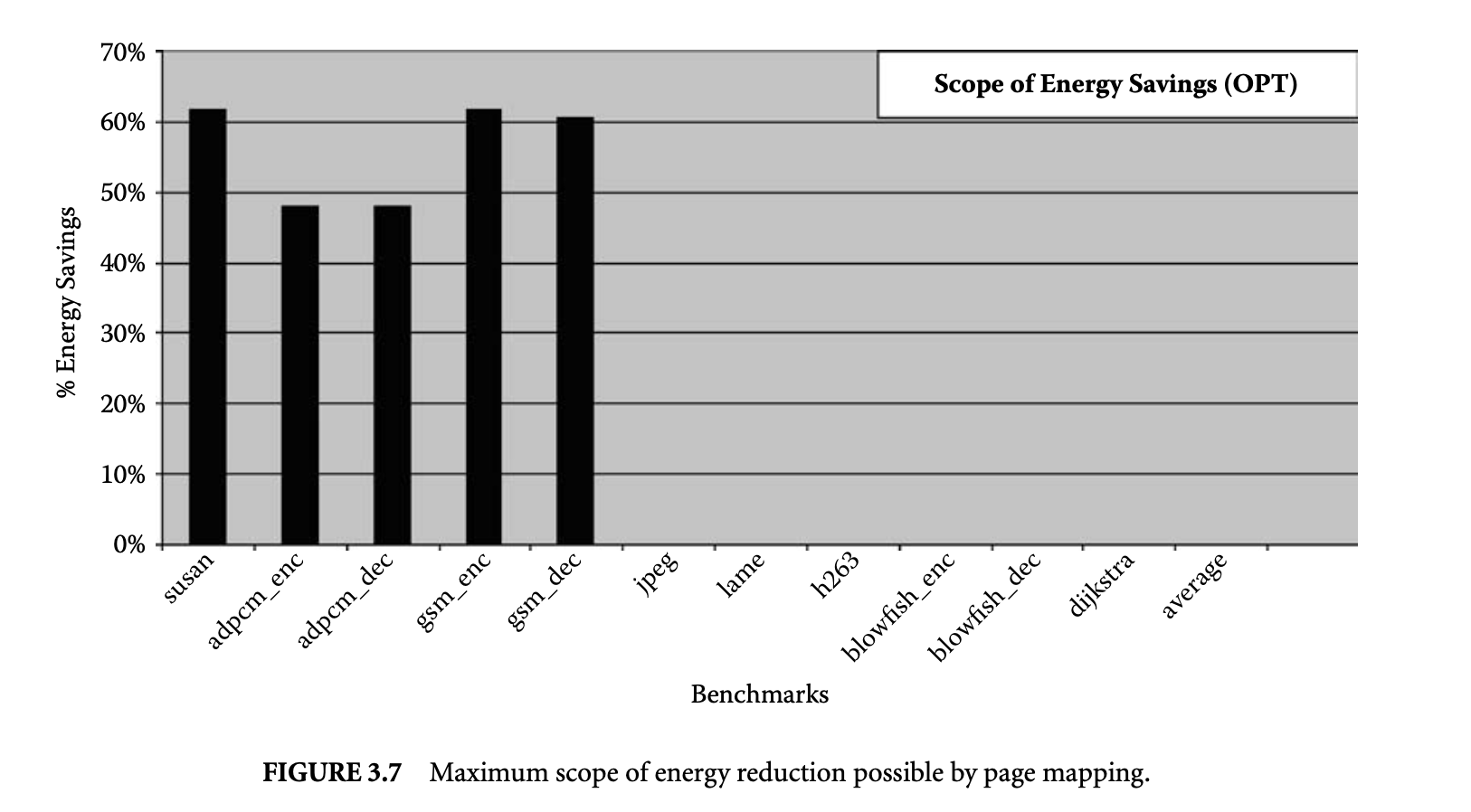
To study the maximum scope of energy reduction achievable by page partitioning, we try all possible page partitions and estimate their energy consumption. Figure 3.7 plots the maximum energy reduction that we achieved by exhaustive exploration of all possible page mappings. We find the page partition that results in the minimum energy consumption by the memory subsystem and plot the reduction obtained compared to the case when all the pages are mapped to the main cache. Since the number of page partitions possible is exponential on the number of pages accessed by the application, it was not possible to complete the simulations for all the benchmarks. Exhaustive exploration was possible only for the first five benchmarks. The plot shows that compared to the case when all pages are mapped to the main cache, the scope of energy reduction is 55% on this set of benchmarks.
Encouraged by the effectiveness of page mapping, we developed several heuristics to partition the pages and see if it is possible to achieve high degrees of energy reduction using much faster techniques.
3.4.3.2 Complex Page Partitioning Heuristic: OM2N
The first technique we developed and examined is the heuristic OM2N, which is a greedy heuristic with one level of backtracking. Figure 3.8 describes the OM2N heuristic. Initially, (list of pages mapped to the main cache) and (list of pages mapped to the mini-cache) are empty. All the pages are initially undecided

and are in (line 01). is a list containing pages sorted in decreasing order of accesses. The heuristic picks the first page in and tries both the mappings of this page -- first to the main cache (line 04) and then to the mini-cache (line 11). In lines 05 to 10, after mapping the first page to the main cache, the while loop tries to map each of the remaining pages one by one into the main cache (line 07) and the mini-cache (line 08) and keeps the best solution. Similarly, it tries to find the best page partition in lines 12 to 17 after assuming that the first page is mapped to the mini-cache and remembers the best solution. In lines 18 to 20 it evaluates the energy reduction achieved by the two assumptions. The algorithm finally decides on the mapping of the first page in line 20 by mapping the first page into the cache that leads to lesser energy consumption.
The function evaluatePartitionCost(M, m) uses simulation to estimate the performance or the energy consumption of a given partition. The simulation complexity, and therefore the complexity of the function evaluatePartitionCost(M, m), is O(). In each iteration of the topmost while loop in lines 02 to 21, the mapping of one page is decided. Thus, the topmost while loop in lines 02 to 21 is executed at most times. In each iteration of the while loop, the two while loops in lines 05 to 10 and lines 12 to 17 are executed. Each of these while loops may call the function evaluatePartitionCost(M, m) at most times. Thus, the time complexity of heuristic OM2N is O().
Figure 19 plots the energy reduction achieved by the minimum energy page partition found by our heuristic OM2N compared to the energy consumption when all the pages are mapped to the main cache. The main observation from Figure 19 is that the minimum energy achieved by the exhaustive and the OM2N is almost the same. On average, OM2N can achieve a 52% reduction in memory subsystem energy consumption.
3.4.3 Simple Page Partitioning Heuristic: OMN
Encouraged by the fact the algorithm of complexity O() can discover page mappings that result in near-optimal energy reductions, we tried to develop simpler and faster algorithms to partition the pages. Figure 20 is a greedy approach for solving the data partitioning problem. The heuristic picks the first page in and evaluates the cost of the partition when the page is mapped to the main cache (line 04) and when it is mapped to the mini-cache (line 05). The heuristic finally maps a page to the partition that results in minimum cost (line 06). There is only one while loop in this algorithm (lines 02 to 07), and in each step it decides upon the mapping of one page. Thus, it performs at most simulations, each of complexity . Thus, the complexity of this heuristic OMN is .

The leftmost bars in Figure 11 plot the energy reduction achieved by the minimum energy page partition found by our heuristic OMN compared to the energy consumption when all the pages are mapped to the main cache. On average, OMN can discover page mappings that result in a 50% reduction in memory subsystem energy consumption.
3.4.3.4 Very Simple Page Partitioning Heuristic: ON
Figure 12 shows a very simple single-step heuristic. If we define , then the first pages with the maximum number of accesses are mapped to the mini-cache, and the rest are mapped to the main cache. This partition aims to achieve energy reduction while making sure there is no performance loss (for high-associativity mini-caches). Note that for this heuristic we do not need to sort the list of all the pages. Only pages with the highest number of accesses are required. If the number of pages is , then the time complexity of selecting the pages with highest accesses is . Thus, the complexity of the heuristic is only , which can be approximated to , since both and are very small compared to .

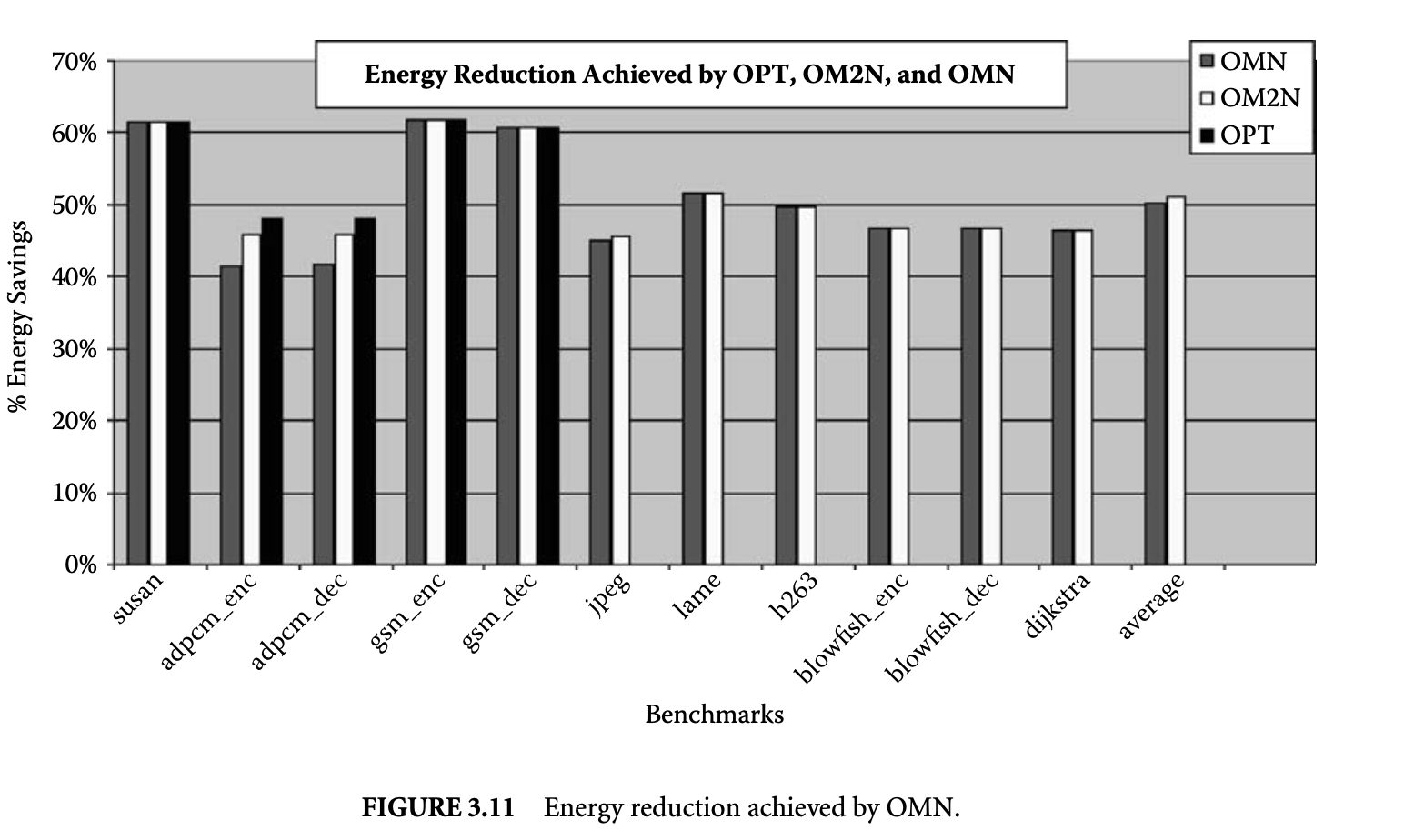
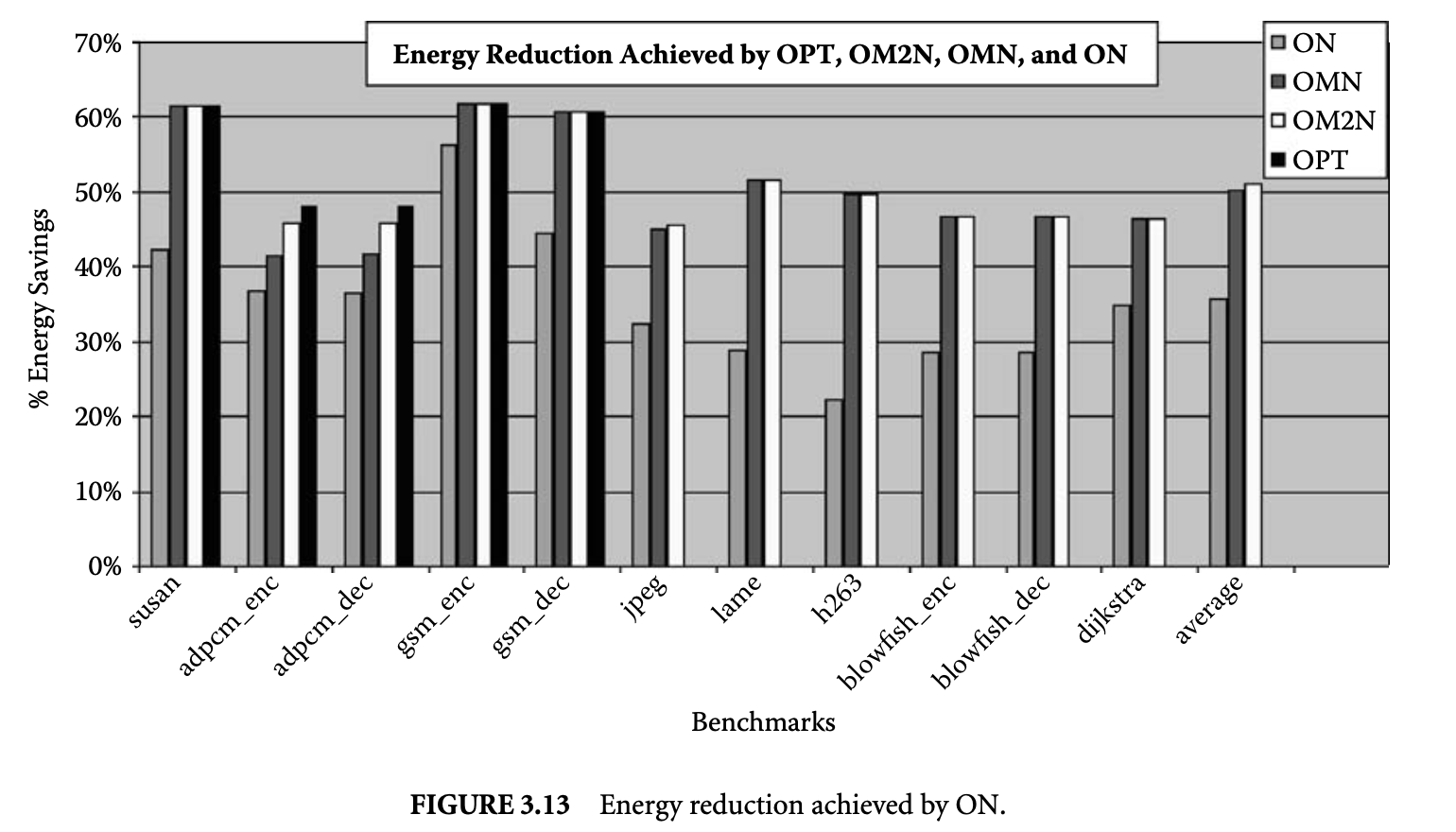
Figure 13 plots the energy reduction achieved by the minimum energy page partition found by our heuristic OMN compared to the energy consumption when all the pages are mapped to the main cache. On average, OMN can discover page mappings that result in a 5% reduction in memory subsystem energy consumption.
The leftmost bars in Figure 13 plot the energy reduction obtained by the lowest-energy-consuming page partition discovered by the ON heuristic compared to when all the pages are mapped to the main cache. Figure 13 shows that ON could not obtain as impressive results as the previous more complex heuristics. On average, the ON heuristic achieves only a 35% energy reduction in memory subsystem energy consumption.
3.4.3.5 Goodness of Page Partitioning Heuristics
We define the goodness of a heuristic as the energy reduction achieved by it compared to the maximum energy reduction that is possible, that is, , where is the energy consumption when all the pages are mapped to the main cache, is the energy consumption of the best energy partition the heuristic found, and is the energy consumption of the best energy partition. Figure 14 plots the goodness of the ON and OMN heuristic in obtaining energy reduction. For the last seven benchmarks for which we could not perform the optimal search. We assume the partition found by the heuristic OM2N is the best energy partition. The graph shows that the OMN heuristic could obtain on average 97% of the possible energy reduction, while ON could achieve on average 64% of the possible energy reduction. It is important to note that the GCC compiler for XScale does not exploit the mini-cache at all. The ON heuristic provides a simple yet effective way to exploit the mini-cache without incurring any performance penalty (for a high-associativity mini-cache).

3.4.4 Optimizing for Energy Is Different Than Optimizing for Performance
This experiment investigates the difference in optimizing for energy and optimizing for performance. We find the partition that results in the least memory latency and the partition that results in the least energy consumption. Figure 3.15a plots , where is the memory subsystem energy consumption of the partition that results in the least memory latency, and is the memory subsystem energy consumption by the partition that results in the least memory subsystem energy consumption. For the first five benchmarks (susan to gsm_dec), the number of pages in the footprint were small, so we could explore all the partitions. For the last seven benchmarks (jpeg to dijkstra), we took the partition found by the OM2N heuristic as the best partition, as OM2N gives close-to-optimal results in cases when we were able to search optimally. The graph essentially plots the increase in energy if you choose the best performance partition as your design point. The increase in energy consumption is up to 130% and on average is 58% for this set of benchmarks.
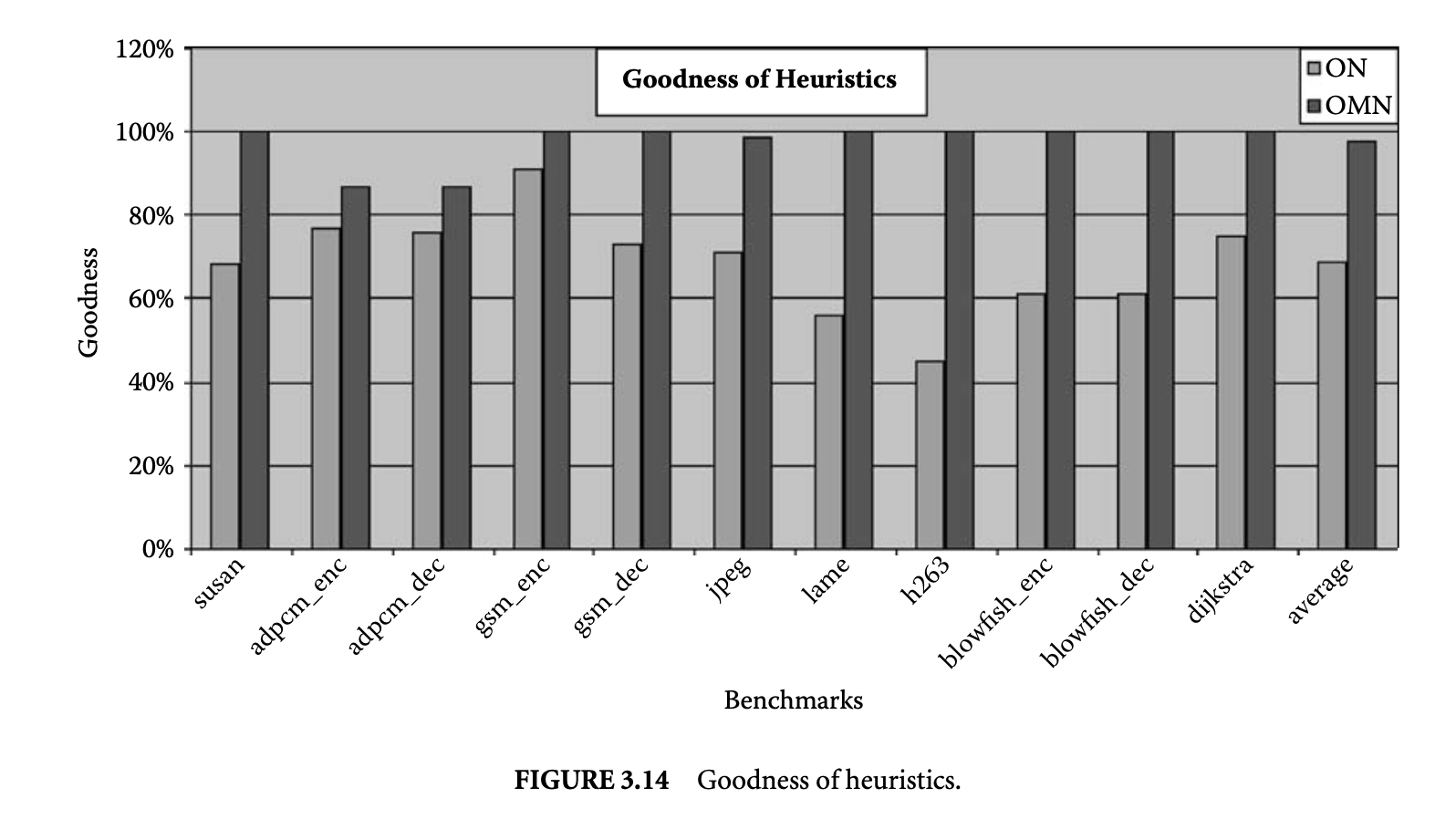
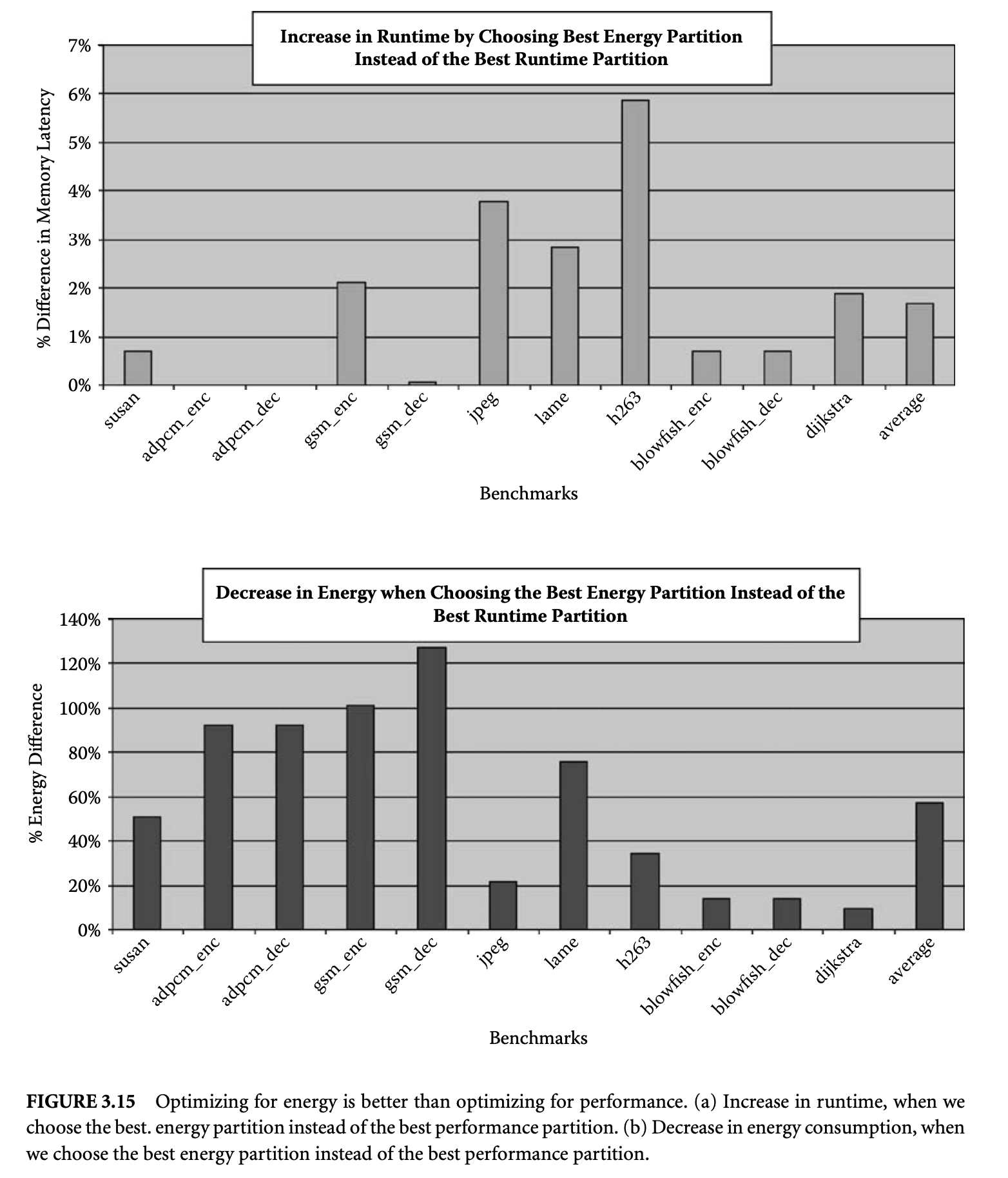
Figure 3.15: Optimizing for energy is better than optimizing for performance. (a) Increase in runtime, when we choose the best. energy partition instead of the best performance partition. (b) Decrease in energy consumption, when we choose the best energy partition instead of the best performance partition.
Figure 3.15b plots , where is the memory latency (in cycles) of the best energy partition, and is the memory latency of the best-performing partition. This graph shows the increase in memory latency when you choose the best energy partition compared to using the best performance partition. The increase in memory latency is on average 1.7% and is 5.8% in the worst case for this set of benchmarks. Thus, choosing the best energy partition results in significant energy savings at a minimal loss in performance.
3.5 Compiler-in-the-Loop HPC Design
So far we have seen that HPC is a very effective microarchitectural technique to reduce the energy consumption of the processor. The energy savings achieved are very sensitive to the HPC configuration; that is, if we change the HPC configuration, the page partitioning should also change.
In the traditional DSE techniques, for example, SO DSE, the binary and the page mapping are kept the same, and the binary with the page mapping is executed on different HPC configurations. This strategy is not useful for HPC DSE, since it does not make sense to use the same page mapping after changing the HPC parameters. Clearly, the HPC parameters should be explored with the CIL during the exploration. To evaluate HPC parameters, the page mapping should be set to the given HPC configuration.
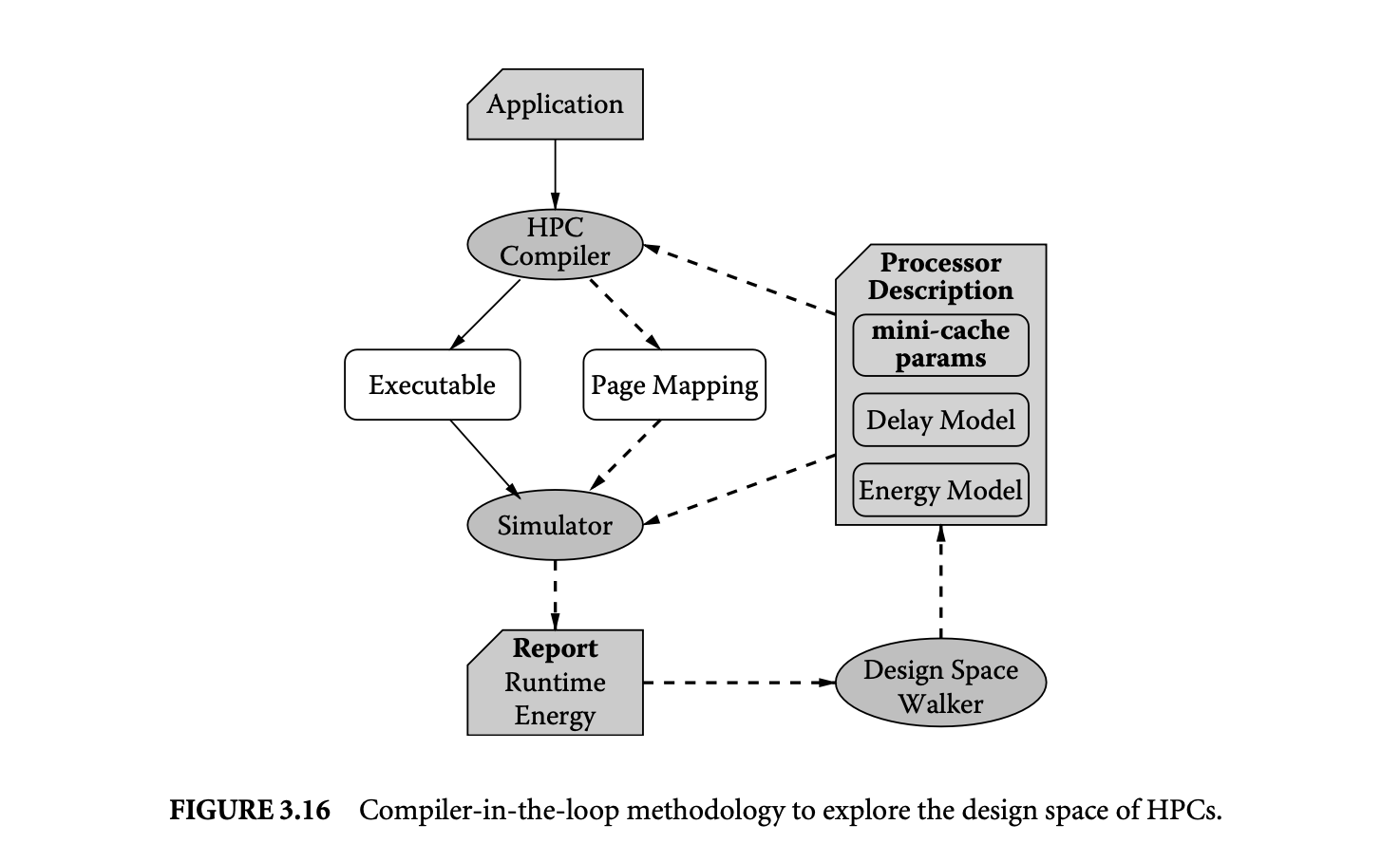
Our CIL DSE framework to explore HPC parameters is depicted in Figure 3.16. The CIL DSE framework is centered around a textual description of the processor. For our purposes, the processor description contains information about (a) HPC parameters, (b) the memory subsystem energy models, and (c) the processor and memory delay models.
We use the OMN page partitioning heuristic and generate a binary executable along with the page mapping. The page mapping specifies to which cache (main or mini) each data memory page is mapped. The compiler is tuned to generate page mappings that lead to the minimum memory subsystem energy consumption. The executable and the page mapping are both fed into a simulator that estimates the runtime and the energy consumption of the memory subsystem.
The Design Space Walker performs HPC design space exploration by updating the HPC design parameters in the processor description. The mini-cache, which is configured by Design Space Walker, is specified using two attributes: the mini-cache size and the mini-cache associativity. For our experiments, we vary cache size from 256 bytes to 32 KB, in exponents of 2. We explore the whole range of mini-cache associativities, that is, from direct mapped to fully associative. We do not model the mini-cache configurations

for which eCACTI [23] does not have a power model. We set the cache line size to be 32 bytes, as in the Intel XScale architecture. In total we explore 33 mini-cache configurations for each benchmark.
3.5.1 Exhaustive Exploration
We first present experiments to estimate the importance of exploration of HPCs. To this end, we perform exhaustive CIL exploration of HPC design space and find the minimum-energy HPC design parameters. Figure 3.17 describes the exhaustive exploration algorithm. The algorithm estimates the energy consumption for each mini-cache configuration (line 02) and keeps track of the minimum energy. The function estimate_energy estimates the energy consumption for a given mini-cache size and associativity.
Figure 3.18 compares the energy consumption of the memory subsystem with three cache designs. The leftmost bar represents the energy consumed by the memory subsystem when the system has only a 32KB
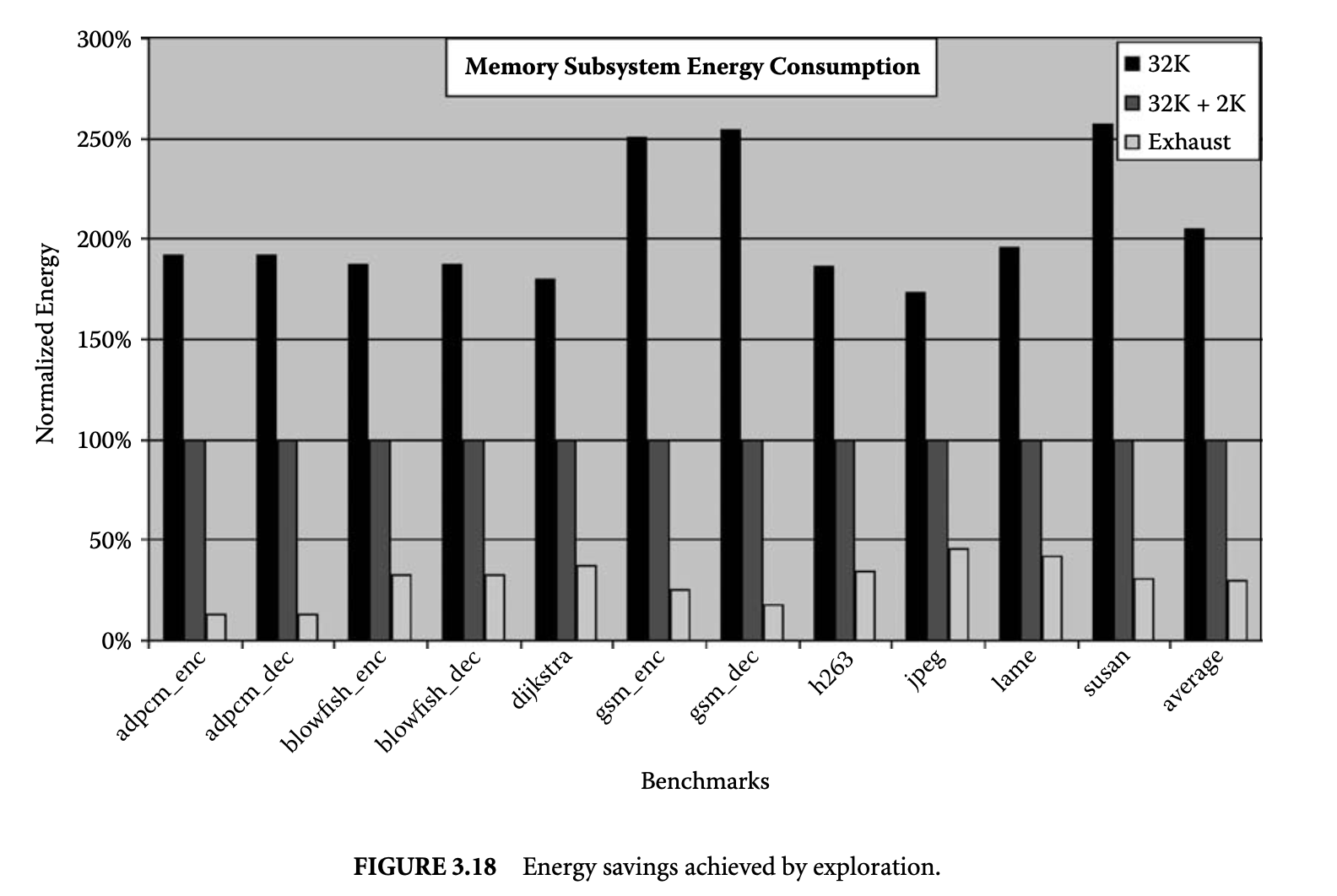
main cache (no mini-cache is present.) The middle bar shows the energy consumed when there is a 2KB mini-cache in parallel with the 32KB cache, and the application is compiled to achieve minimum energy. The rightmost bar represents the energy consumed by the memory subsystem, when the mini-cache parameters (size and associativity) are chosen using exhaustive CIL exploration. All the energy values are normalized to the case when there is a 2KB mini-cache (the Intel XScale configuration). The last set of bars is the average over the applications.
We make two important observations from this graph. The first is that HPC is very effective in reducing the memory subsystem energy consumption. Compared to not using any mini-cache, using a default mini-cache (the default mini-cache is 2KB, 32-way set associative) leads to an average of a 2 times reduction in the energy consumption of the memory subsystem. The second important observation is that the energy reduction obtained using HPCs is very sensitive to the mini-cache parameters. Exhaustive CIL exploration of the mini-cache DSE to find the minimum-energy mini-cache results in an additional 80% energy reduction, thus reducing the energy consumption to just 20% of the case with a 2KB mini-cache.
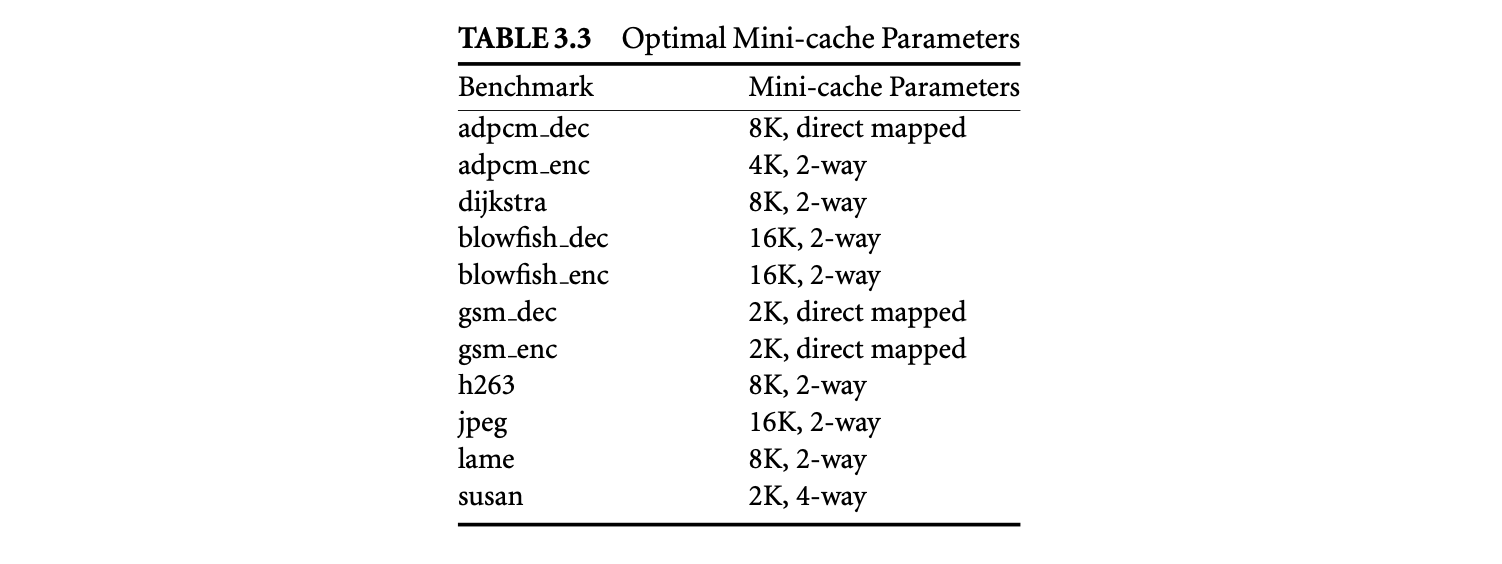
Furthermore, the performance of the energy-optimal HPC configuration is very close to the performance of the best-performing HPC configuration. The performance degradation was no more than 5% and was 2% on average. Therefore, energy-optimal HPC configuration achieves high energy reductions at minimal performance cost. Table 3.3 shows the energy-optimal mini-cache configuration for each benchmark. The table suggests that low-associativity mini-caches are good candidates to achieve low-energy solutions.
3.5.2 HPC CIL DSE Heuristics
We have demonstrated that CIL DSE of HPC design parameters is very useful and important to achieve significant energy savings. However, since the mini-cache design space is very large, exhaustive exploration may consume a lot of time. In this section we explore heuristics for effective and efficient HPC DSE.
3.5.2.1 Greedy Exploration
The first heuristic we develop for HPC CIL DSE is a pure greedy algorithm, outlined in Figure 3.19. The greedy algorithm first greedily finds the cache size (lines 02 to 04) and then greedily finds the associativity (lines 05 to 07). The function betterNewConfiguration tells whether the new mini-cache parameters result in lower energy consumption than the old mini-cache parameters.
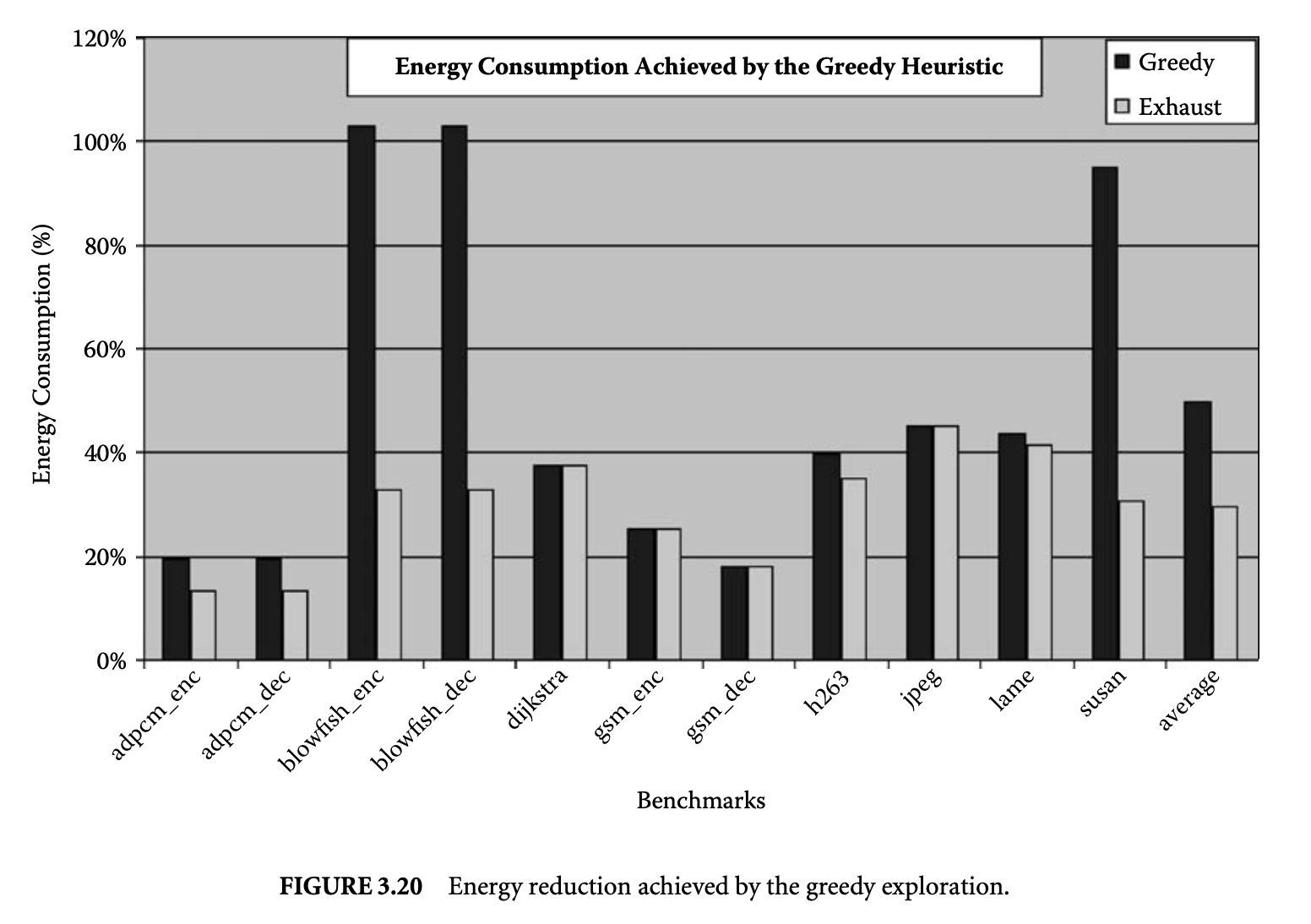
Figure 3.20 plots the energy consumption when the mini-cache configuration is chosen by the greedy algorithm compared to when using the default 32KB main cache and 2KB mini-cache configuration. The plot shows that for most applications, greedy exploration is able to achieve good results, but for blowfish and susan, the greedy exploration is unable to achieve any energy reduction; in fact, the solution it has found consumes even more energy than the base configuration. However, on average, the greedy CIL HPC DSE can reduce the energy consumption of the memory subsystem by 50%.



3.5.2.2 Hybrid Exploration
To achieve energy consumption close to the optimal configurations, we developed a hybrid algorithm, outlined in Figure 3.21. The hybrid algorithm first greedily searches for the optimal mini-cache size (lines 02 to 04). Note, however, that it tries every alternate mini-cache size. The hybrid algorithm tries mini-cache sizes in exponents of 4, rather than 2 (line 03). Once it has found the optimal mini-cache size, it explores exhaustively in the size-associativity neighborhood (lines 07 to 15) to find a better size-associativity configuration.
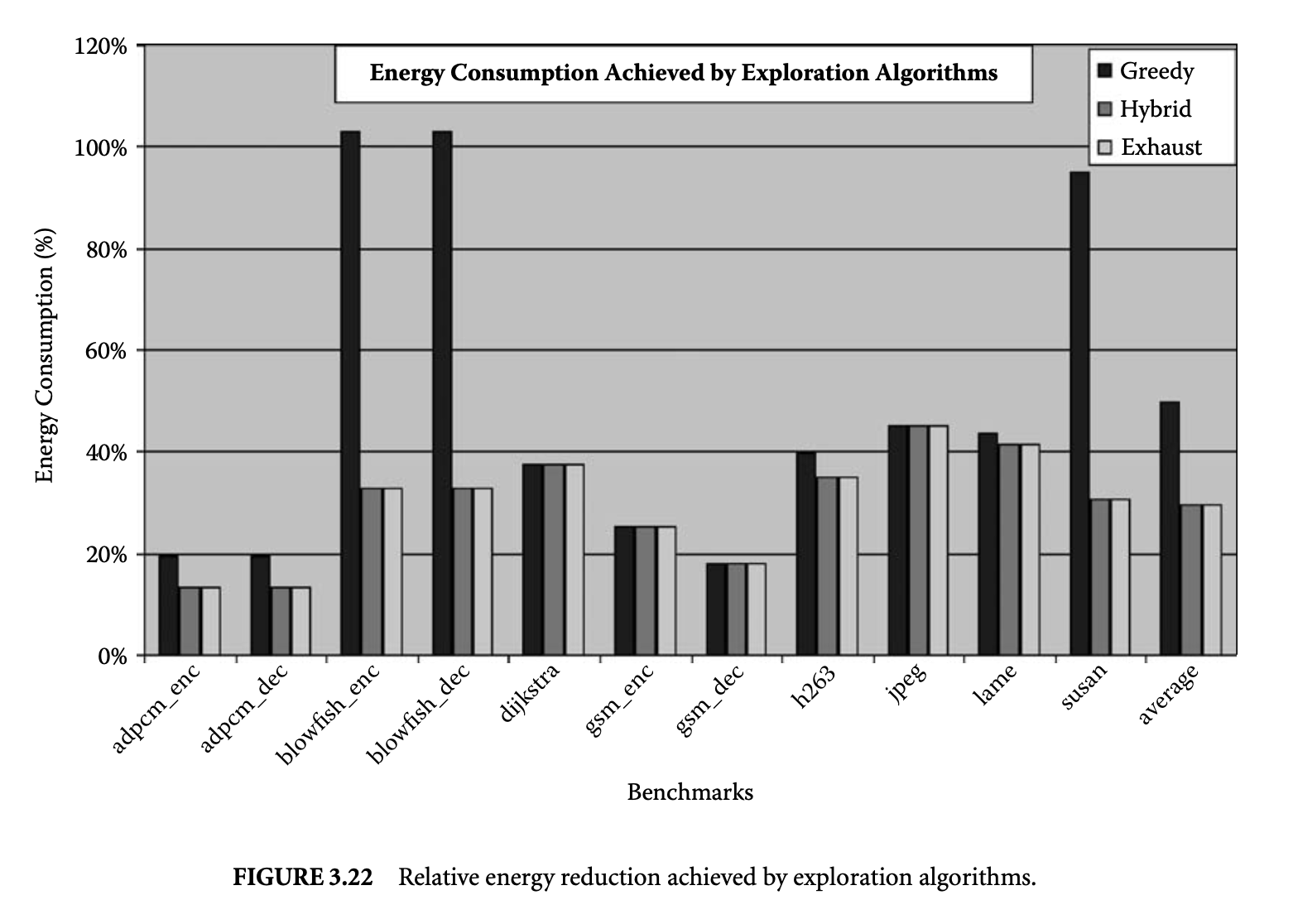
The middle bar in Figure 3.22 plots the energy consumption of the optimal configuration compared to the energy consumption when the XScale default 32-way, 2K mini-cache is used and compares the energy reductions achieved with the greedy and exhaustive explorations. The graph shows that the hybrid exploration can always find the optimal HPC configuration for our set of benchmarks.
3.5.2.3 Energy Reduction and Exploration Time Trade-Off
There is a clear trade-off between the energy reductions achieved by the exploration algorithms and the time required for the exploration. The rightmost bar in Figure 3.23 plots the time (in hours) required to explore the design space using the exhaustive algorithm. Although the exhaustive algorithm is able to discover extremely low energy solutions, it may take tens of hours to perform the exploration. The leftmost bar in Figure 3.23 plots the time that greedy exploration requires to explore the design space of the mini-cache. Although the greedy algorithm reduces the exploration time on average by a factor of 5 times, the energy consumption is on average 2 times more than what is achieved by the optimal algorithm.
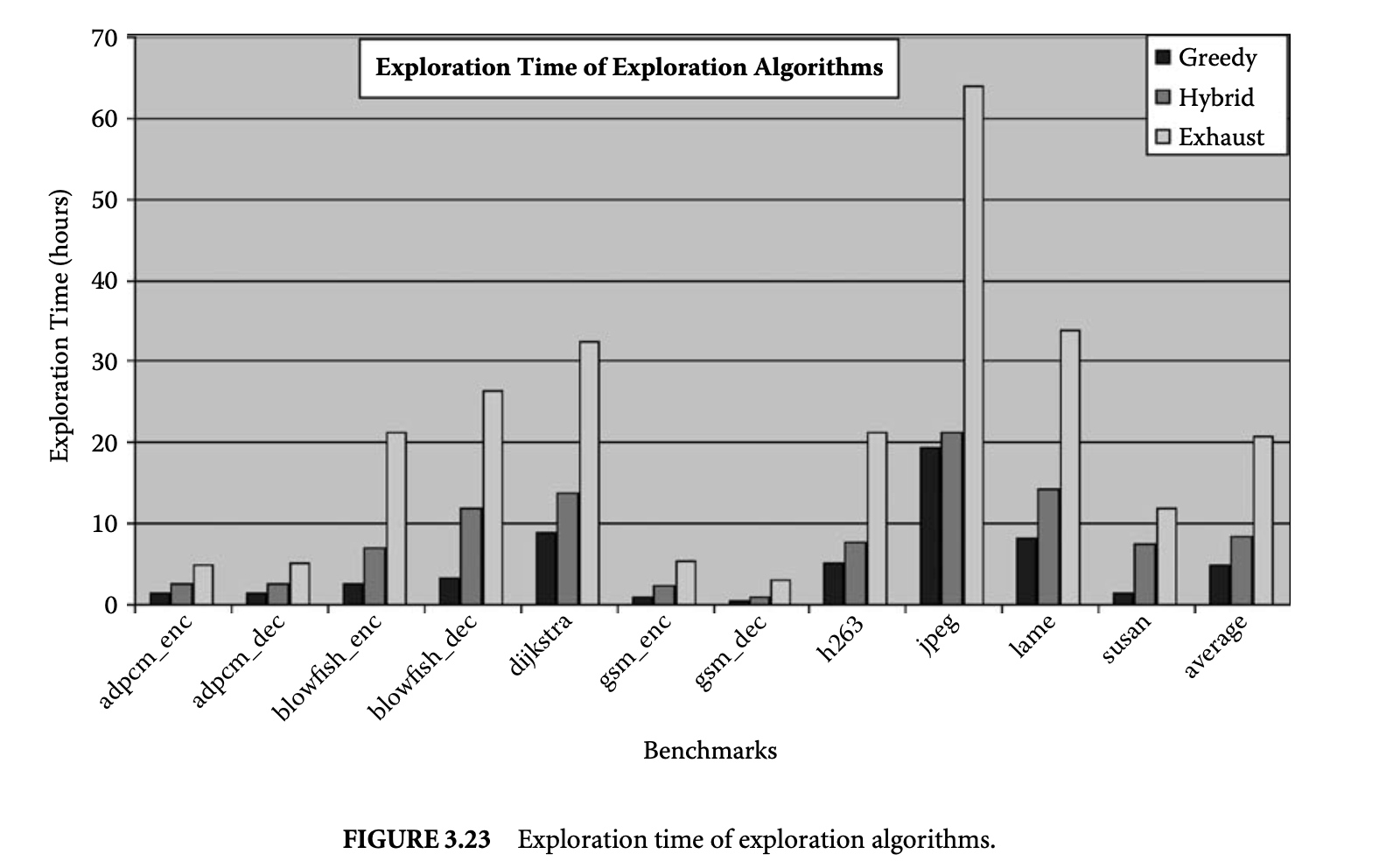
Finally, the middle bar in Figure 3.23 plots the time required to find the mini-cache configuration when using the hybrid algorithm. Our hybrid algorithm is able to find the optimal mini-cache configuration in all of our benchmarks, while it takes about 3 times less time than the optimal algorithm. Thus, we believe the hybrid exploration is a very effective and efficient exploration technique.
3.5.3 Importance of Compiler-in-the-Loop DSE
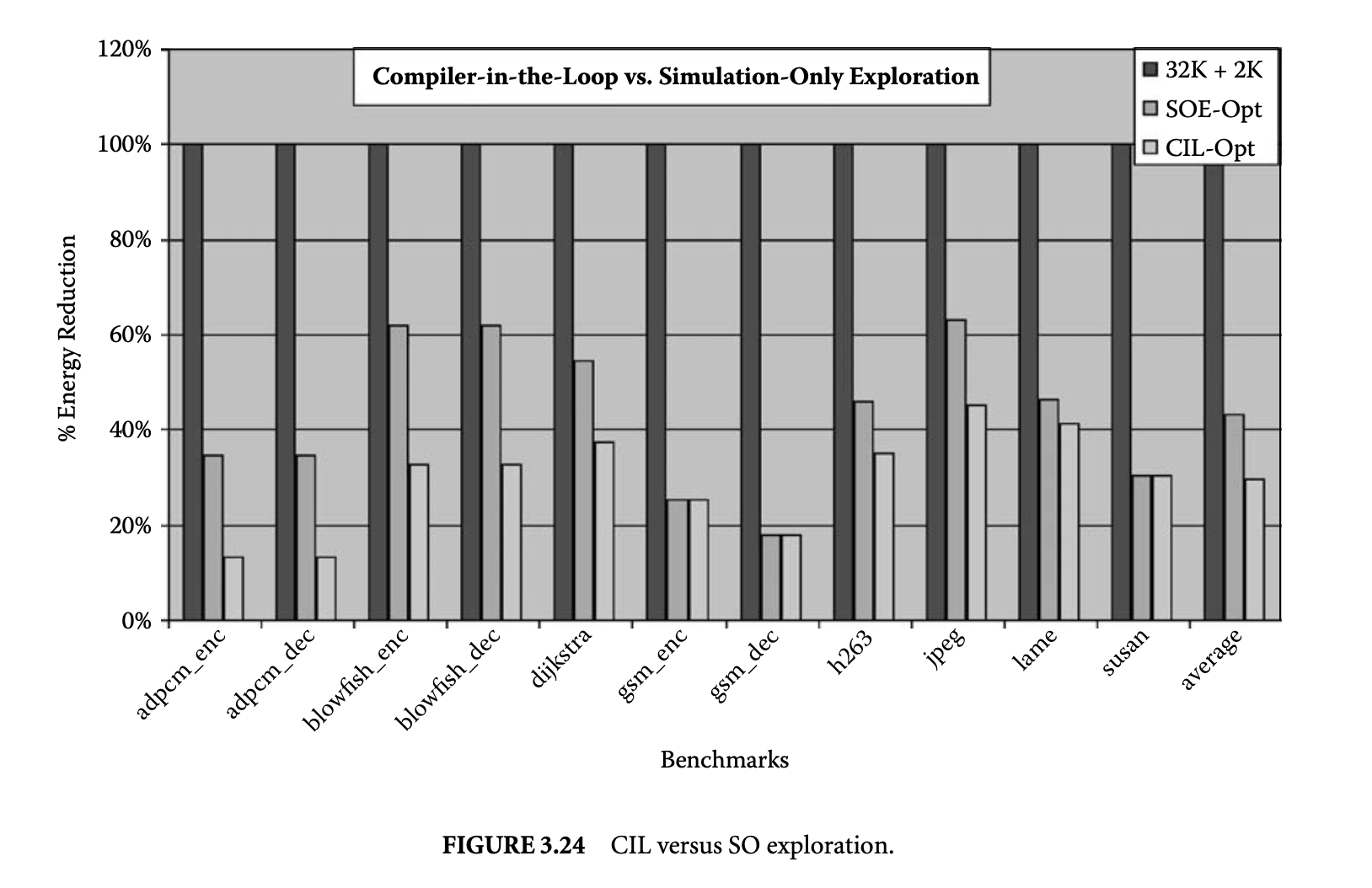
Our next set of experiments show that although SO DSE can also find HPC configurations with less memory subsystem energy consumption, it does not do as well as CIL DSE. To this end, we performed SO DSE of HPC design parameters. We compile once for the 32KB/2KB (i.e., the original XScale cache configuration) to obtain an executable and the minimum energy page mapping. While keeping these two the same, we explored all the HPC configurations to find the HPC design parameters that minimize the memory subsystem energy consumption. Figure 3.24 plots the the energy consumption of the HPC configuration found by the SO DSE (middle bar) and CIL DSE (right bar) and the original Intel XScale HPC configuration (left bar) for each benchmark. The rightmost set of bars represents the average over all the benchmarks. All the energy consumption values are normalized to energy consumption of the 32KB/2KB configuration.
It should be noted that the overhead of compilation time in CIL DSE is negligible, because simulation times are several orders of magnitude more than compilation times. The important observation to make from this graph is that although even SO DSE can find HPC configurations that result in, on average, a 57% memory subsystem energy reduction, CIL DSE is much more effective and can uncover HPC configurations that result in a 70% reduction in the memory subsystem energy reduction.
3.6 Summary
Embedded systems are characterized by stringent, application-specific, multidimensional constraints on their designs. These constraints, along with the shrinking time to market and frequent upgrade needs of embedded systems, are responsible for programmable embedded systems that are highly customized. While code generation for these highly customized embedded systems is a challenge, it is also very rewarding in the sense that an architecture-sensitive compilation technique can have significant impact on the system power, performance, and so on. Given the importance of the compiler on the system design parameters, it is reasonable for the compiler to take part in designing the embedded system. While it is possible to use ad hoc methods to include the compiler effects while designing an embedded system, a systematic methodology to design embedded processors is needed. This chapter introduced the CIL design methodology, which systematically includes the compiler in the embedded system DSE. Our methodology requires an architecture-sensitive compiler. To evaluate a design point in the embedded system design space, the application code is first compiled for the embedded system design and is then executed on the embedded system model to estimate the various design parameters (e.g., power, performance, etc.). Owing to the lack of compiler technology for embedded systems, most often, first an architecture-sensitive compilation technique needs to be developed, and only then can it be used for CIL design of the embedded processor. In the chapter we first developed a compilation technique for HPCs, which can result in a 50% reduction in the energy consumption of the memory subsystem. When we use this compilation technique in our CIL approach, we can come up with HPC parameters that result in an 80% reduction in the energy consumption by the memory subsystem, demonstrating the need and usefulness of our approach.
References
[1] M. R. Barbacci. 1981. Instruction set processor specifications (ISPS): The notation and its applications. IEEE Transactions on Computing C-30(1):24-40. New York: IEEE Press.
[2] D. Burger and T. M. Austin. 1997. The SimpleScalar tool set, version 2.0. SIGARCH Computer Architecture News 25(3):13-25.
[3] L. T. Clark, E. J. Hoffman, M. Biyani, Y. Liao, S. Strazdus, M. Morrow, K. E. Velarde, and M. A. Yarch. 2001. An embedded 32-b microprocessor core for low-power and high-performance applications. IEEE J. Solid State Circuits 36(11):1599-608. New York: IEEE Press.
[4] Paul C. Clements. 1996. A survey of architecture description languages. In Proceedings of International Workshop on Software Specification and Design (IWSSD), 16-25.
[5] A. Fauth, M. Freericks, and A. Knoll. 1993. Generation of hardware machine models from instruction set descriptions. In IEEE Workshop on VLSI Signal Processing, 242-50.
[6] A. Gonzalez, C. Aliagas, and M. Valero. 1995. A data cache with multiple caching strategies tuned to different types of locality. In ICS '95: Proceedings of the 9th International Conference on Supercomputing, 338-47. New York: ACM Press.
[7] M. R. Guthaus, J. S. Ringenberg, D. Ernst, T. M. Austin, T. Mudge, and R. B. Brown. 2001. MiBench: A free, commercially representative embedded benchmark suite. In IEEE Workshop in Workload Characterization.
[8] J. Gyllenhaal, B. Rau, and W. Hwu. 1996. HMDES version 2.0 specification. Tech. Rep. IMPACT-96-3, IMPACT Research Group, Univ. of Illinois, Urbana.
[9] G. Hadjiyiannis, S. Hanono, and S. Devadas. 1997. ISDL: An instruction set description language for retargetability. In Proceedings of Design Automation Conference (DAC), 299-302. New York: IEEE Press.
[10] A. Halambi, P. Grun, V. Ganesh, A. Khare, N. Dutt, and A. Nicolau. 1999. EXPRESSION: A language for architecture exploration through compiler/simulator retargetability. In Proceedings of Design Automation and Test in Europe. New York: IEEE Press.
[11] A. Halambi, A. Shrivastava, P. Biswas, N. Dutt, and A. Nicolau. 2002. A design space exploration framework for reduced bit-width instruction set architecture (risa) design. In ISS '02: Proceedings of the 15th International Symposium on System Synthesis, 120-25. New York: ACM Press.
[12] A. Halambi, A. Shrivastava, P. Biswas, N. Dutt, and A. Nicolau. 2002. An efficient compiler technique for code size reduction using reduced bit-width isas. In Proceedings of the Conference on Design, Automation and Test in Europe. New York: IEEE Press.
[13] A. Halambi, A. Shrivastava, N. Dutt, and A. Nicolau. 2001. A customizable compiler framework for embedded systems. In Proceedings of SCOPES.
[14] Hewlett Packard. HP iPAQ 14000 series-system specifications. http://www.hp.com.
[15] Intel Corporation. Intel PXA255 processor: Developer's manual. http://www.intel.com/design/pca/applicationsprocessors/manuals/278693.htm.
[16] Intel Corporation. Intel StrongARM SA-1110 microprocessor brief datasheet. http://download.intel.com/design/strong/datashts/27824105.pdf.
[17] Intel Corporation. Intel XScale(R) Core: Developer's manual. http://www.intel.com/design/intelxscale/273473.htm.
[18] Intel Corporation. LV/ULV Mobile Intel Pentium III Processor-M and LV/ULV Mobile Intel Celeron Processor (0.13u)/Intel 440MX Chipset: Platform design guide. http://www.intel.com/design/mobile/desguide/251012.htm.
[19]IPC-D-317A: Design guidelines for electronic packaging utilizing high-speed techniques. 1995. Institute for Interconnecting and Packaging Electronic Circuits.
[20] D. Kastner. 2000. TDL: A hardware and assembly description language. Tech. Rep. TDL 1.4, Saarland University, Germany.
[21] R. Leupers and P. Marwedel. 1998. Retargetable code generation based on structural processor descriptions. Design Automation Embedded Syst. 3(1):75-108. New York: IEEE Press.
[22] K. Lillevold et al. 1995. H.263 test model simulation software. Telenor R&D.
[23] M. Mamidipaka and N. Dutt. 2004. eCACTI: An enhanced power estimation model for on-chip caches. Tech. Rep. TR-04-28, CECS, UCI.
[24] Micron Technology, Inc. MICRON Mobile SDRAM MT48V8M32LF datasheet. http://www.micron.com/products/dram/mobilesdram/.
[25] P. Mishra, A. Shrivastava, and N. Dutt. 2004. Architecture description language (adl)-driven software toolkit generation for architectural exploration of programmable socs. In DAC '04: Proceedings of the 41st Annual Conference on Design Automation, 626-58. New York: ACM Press.
[26] S. Park, E. Earlie, A. Shrivastava, A. Nicolau, N. Dutt, and Y. Paek. 2006. Automatic generation of operation tables for fast exploration of bypasses in embedded processors. In DATE '06: Proceedings of the Conference on Design, Automation and Test in Europe, 1197-202. Leuven, Belgium: European Design and Automation Association. New York: IEEE Press.
[27] S. Park, A. Shrivastava, N. Dutt, A. Nicolau, Y. Paek, and E. Earlie. 2006. Bypass aware instruction scheduling for register file power reduction, In LCTES 2006: Proceedings of the 2006 ACM SIGPLAN/SIGBED conference on language, compilers, and tool support for embedded systems, 173-81. New York: ACM Press.
[28] P. Shivakumar and N. Jouppi. 2001. Cacti 3.0: An integrated cache timing, power, and area model. WRL Technical Report 2001/2.
[29] A. Shrivastava, P. Biswas, A. Halambi, N. Dutt, and A. Nicolau. 2006. Compilation framework for code size reduction using reduced bit-width isas (risas). ACM Transaction on Design Automation of Electronic Systems 11(1):123-46. New York: ACM Press.
[30] A. Shrivastava and N. Dutt. 2004. Energy efficient code generation exploiting reduced bit-width instruction set architecture. In Proceedings of The Asia Pacific Design Automation Conference (ASPDAC). New York: IEEE Press.
[31] A. Shrivastava, N. Dutt, A. Nicolau, and E. Earlie. 2005. Pbexplore: A framework for compiler-in-the-loop exploration of partial bypassing in embedded processors. In DATE '05: Proceedings of the Conference on Design, Automation and Test in Europe, 1264-69. Washington, DC: IEEE Computer Society.
[32] A. Shrivastava, E. Earlie, N. D. Dutt, and A. Nicolau. 2004. Operation tables for scheduling in the presence of incomplete bypassing. In CODES+ISSS, 194-99. New York: IEEE Press.
[33] A. Shrivastava, E. Earlie, N. Dutt, and A. Nicolau. 2005. Aggregating processor free time for energy reduction. In CODES+ISSS '05: Proceedings of the 3rd IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis, 154-59. New York: ACM Press.
[34] A. Shrivastava, E. Earlie, N. Dutt, and A. Nicolau. 2006. Retargetable pipeline hazard detection for partially bypassed processors, In IEEE Transactions on Very Large Scale Integrated Circuits, 791-801. New York: IEEE Press.
[35] A. Shrivastava, I. Issenin, and N. Dutt. 2005. Compilation techniques for energy reduction in horizontally partitioned cache architectures. In CASS '05: Proceedings of the 2005 International Conference on Compilers, Architectures and Synthesis for Embedded Systems, 90-96. New York: ACM Press.
[36] Starcore LLC. SC1000-family processor core reference.
[37] S. P. Vanderwiel and D. J. Lilja. 2000. Data prefetch mechanisms. ACM Computing Survey (CSUR) 32(2):174-99. New York: ACM Press.
[38] V. Zivojnovic, S. Pees, and H. Meyr. 1996. LISA -- Machine description language and generic machine model for HW/SW co-design. In IEEE Workshop on VLSI Signal Processing, 127-36.